

Who knew that stats would be the bomb?
How do you take Big Data and convert it into actionable information that would help business thrive?
Who knew that Machine learning and data analysis algorithms will benefit those service providers who have accumulated large data volumes about their clients, enabling analysts and marketers obtain impartial insight into customer behavior: how the client activity changes if the company has modified its service or introduced a new one; whether the existing service offering has a weak spot, which needs fixing; who to target at what time!
Here is an example of how the results of a problem-solving session that took place at a datathon was used to make a business decision
Datathon is a hackathon focused on problem-solving using Machine Learning.
A bank provided client data in an anonymized form. The datathon participants were to analyze the datasets by generating multiple hypotheses and identifying the viable ones. The problem was expected to be solved using cluster analysis, a method of unsupervised learning.
Unsupervised Learning – a machine learning algorithm that teaches the computer system to identify inferences in datasets. They would consist of input data without labeled responses. Cluster analysis helps find hidden patterns or grouping in data based on specific parameters. For instance, this could be segmentation of subscribers of a mobile services provider.
Multiparameter Data as Basis for Hypotheses
The team was to make hypotheses using data with disparate input parameters. They included description of the product or service acquired, the amount paid using the credit cards issued by the bank, and user demographics – age and sex. The majority of the data fell into categories based on high-level payment destinations – shops, gas stations, services, etc. Some of the categories had a more detailed level of description, for instance, AliExpress, Uber, Burger King, iTunes. The major hypothesis made by the team was as follows: if they analyzed the user money spending patterns, they would generate a rather informative user portrait.
Data Processing, Pattern and Correlation Analysis
Processing Unlabeled Data

The team analyzed all payment destinations and identified correlations. The inference – the greater the number of identical occurrences in payment destinations, the tighter is the correlation (a heavier connector weight on the pic)
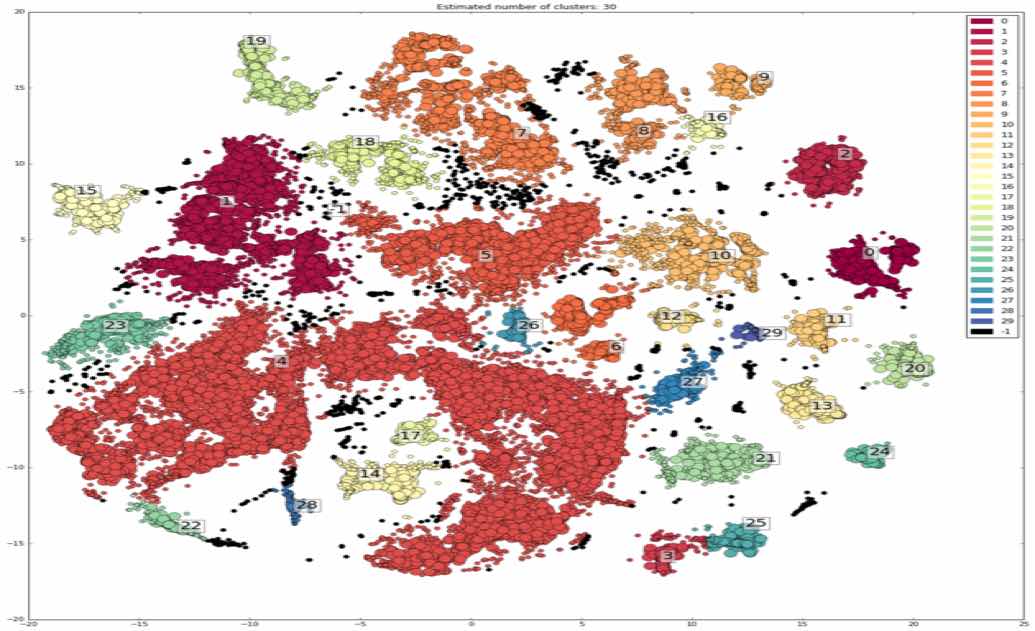
Identifying Patterns and Correlations
The team managed to identify several meaningful patterns and interdependencies. The graph analysis and cluster analysis used by the participants demonstrated a correlation among the clients commuting via Uber and those who shop on iTunes. Another cluster located nearby showed that credit card holders with foreign currency accounts are young people who are regulars at local bars and restaurants.
Unbiased Hypotheses Verification
The Datathon participants test-proved that unsupervised learning is a great fit for validating unbiased hypotheses. This method does not aim to identify cause-and-effect relations or achieve stable results, which otherwise may add subjectivity to the data processing results. For instance, the assumption that an average fast-food lover would frequent different fast-food brands did not prove valid during this problem-solving session.
The topic covered is the result of Olga Babik’s contribution.
Olga Babik is a tech blogger and marketing specialist with Softeq, a software company in Houston, TX. Olga closely collaborates with the Softeq engineering team who work on a variety of IoT projects with the focus on big data mining and machine learning processing at the backend. She highlights her colleagues’ first-hand experience and skills in prototyping, devising, integrating, deploying, and supporting connected solutions driven by firmware, software, and hardware.
No comments:
Post a Comment